一、「台灣西語學習者語料庫」(Corpus de Aprendices Taiwaneses de Español, CATE)
「台灣西語學習者語料庫」(CATE 2005-2017)主要包含「台灣西語學習者書面語語料庫」(Corpus Escrito de Aprendices Taiwaneses de Español, CEATE, 2005-2011)和「台灣西語學習者口語語料庫」(Corpus Oral de Aprendices Taiwaneses de Español, COATE, 2013-2017)。
因應語料庫建構與程式等技術之發展與升級,我們於2018年開始進行西語語料庫系統架構、語料匯入及搜尋功能之重整與處理,並更新爲CATE 2.0。
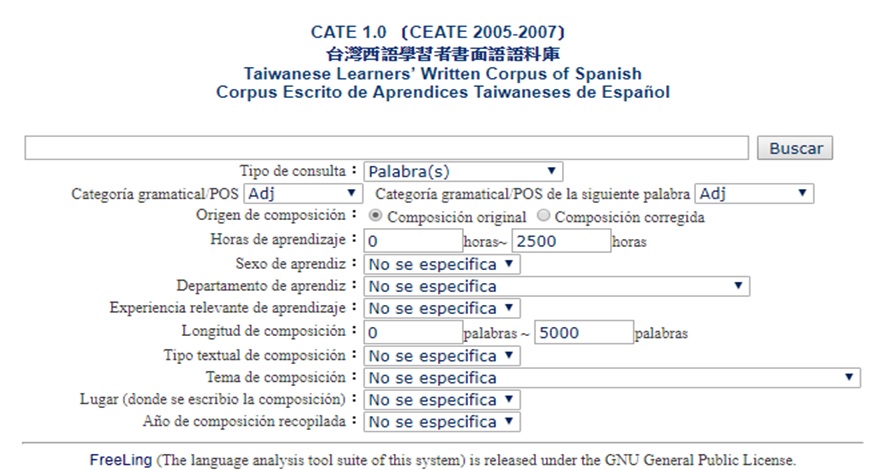
CATE1.0
(Corpus de Aprendices Taiwaneses de Español/台灣西語學習者語料庫1.0):
CEATE
(Corpus Escrito de Aprendices Taiwaneses de Español/
台灣西語學習者書面語語料庫)
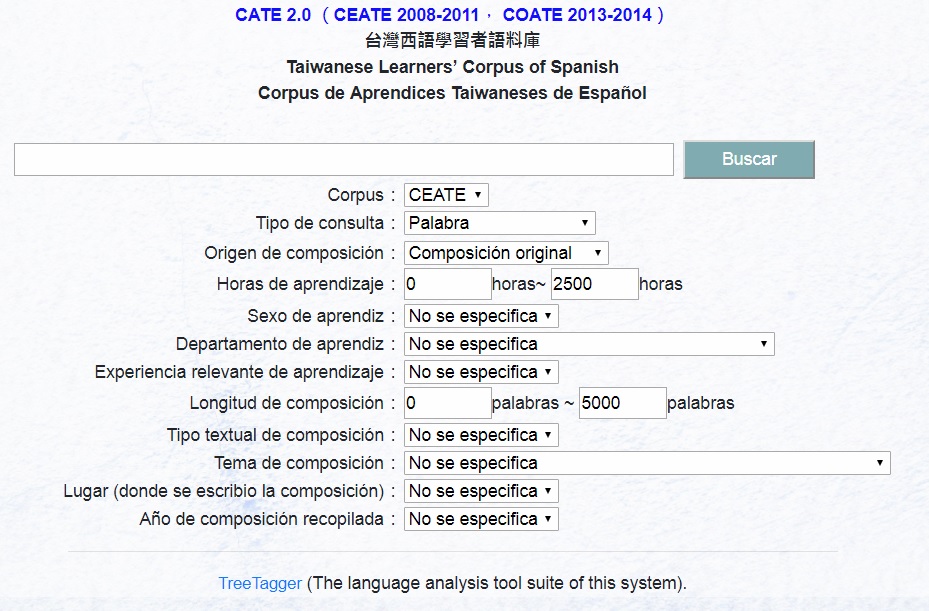
CATE2.0
(Corpus de Aprendices Taiwaneses de Español/台灣西語學習者語料庫2.0):
CEATE 2005-2011 & COATE 2013-2017
(Corpus Escrito de Aprendices Taiwaneses de Español/
台灣西語學習者書面語語料庫 2005-2011 &
Corpus Oral de Aprendices Taiwaneses de Español/
台灣西語學習者口語語料庫2013-2017)
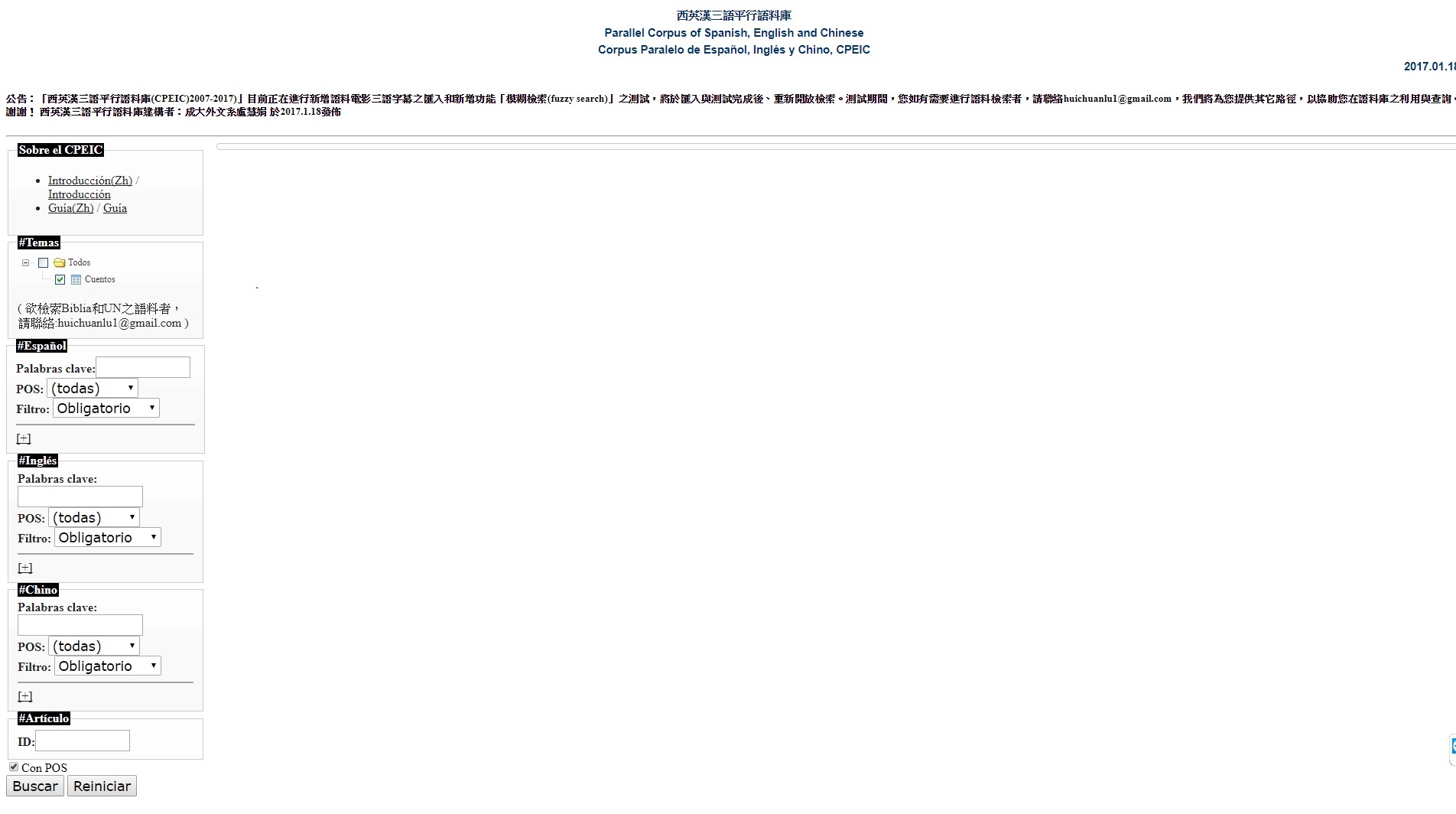
二、「西英漢三語平行語料庫」(Corpus Paralelo de Español, Inglés y Chino, CPEIC)
「西英漢三語平行語料庫」(CPEIC, 2007-2017)含聖經、童話故事、聯合國文件和電影字幕的語料類型,過程歷經由書面語到口語、由雙語到三語、由單機到網路介面等的改變,並於2018年新增「模糊搜尋」功能。
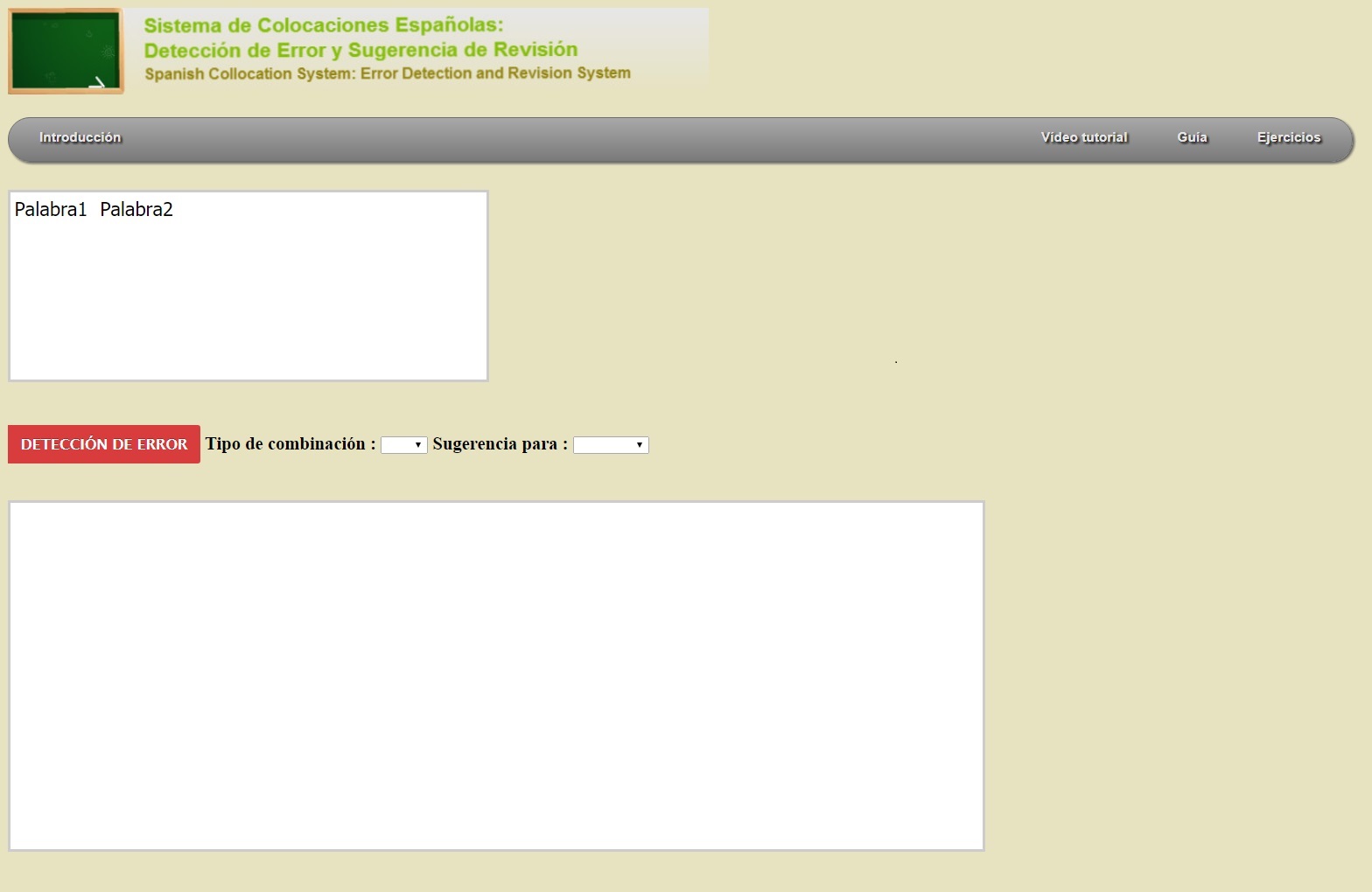
三、「西語的搭配詞錯誤偵測與修正建議系統」
(Sistema de Colocaciones Españolas: Detección de Error y Sugerencia de Revisión/
Spanish Collocation Error Detection and Revision Suggestion, SpColEDRS)
「西語的搭配詞錯誤偵測與修正建議系統」(SpColEDRS, 2015-2016)是針對西語搭配詞學習所開發的輔助工具,主要具有西語搭配詞的錯誤偵測與修正建議兩大功能。
該系統以已建構之語料庫爲基礎,透過機器學習的方式訓練語料,提取高分的搭配詞,再經由人工修正的程式,彙整出搭配詞詞彙庫;可針對特定類型組合、不當使用之搭配詞進行即時偵測錯誤與提供修正錯誤的建議清單做為選擇與參考。這個工具受制於所訓練之語料量,故能偵測的錯誤與提供的修正建議範圍也相對有限。
四、「西語語言測驗輔助系統」(Ser/Estar2018,SE2018)
該系統以過去在西語聯繫動詞SER/ESTAR之習得實驗的研究結果爲基礎,針對學習者在使用「SER/ESTAR+形容詞」結構的正誤率做爲判定難易等級的基礎,再透用戶系統記錄使用者的成績及答錯的題目,並以評量系統針對用戶的答題狀況,適性提供不同難度分布的聼與讀的題目,讓使用者完成西語聯繫動詞之語法點的測試或自評。
五、「語言相似度工具」(Herramienta de Semejanzas entre Lenguas/ Language Similarity Tool, LST)
語言相似度工具可用來計算兩語言間的相似度或距離,目前主要是針對兩兩雙語的關係子句結構所設計,此工具以Visual Studio 2015開發,採用C#程式語言撰寫,並以微軟的Windows作業系統為主要運作環境。未來目標希望能應用到其他結構類型之跨語言相似度的對比估算。此一工具將配合日後的應用範疇調整修改,以擴大使用面向與提升應用效益。